本篇文章介绍如何使用Hadoop调试自己编写的MapReduce程序(Java)。文章以创建一个WordCount程序并进行调试为例,仅涉及操作步骤,不涉及原理和讲解。Hadoop安装配置请参见第一篇文章。
话不多说,直接步入正题:
1. 新建工程。单击菜单File-New-Java Project。
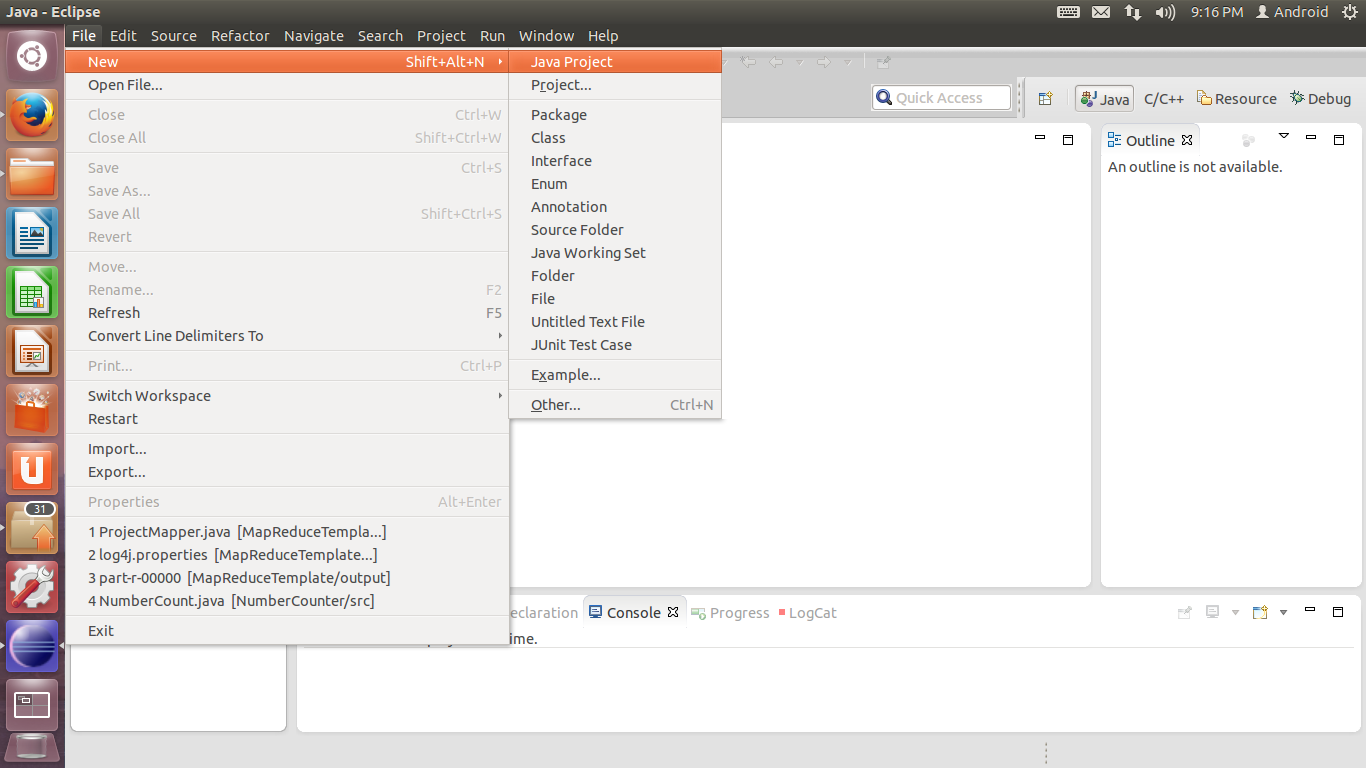
2. 在打开的对话框中,为自己的工程起一个名字,如MapReduceDemo。本页其他设置保持默认值,单击Next。
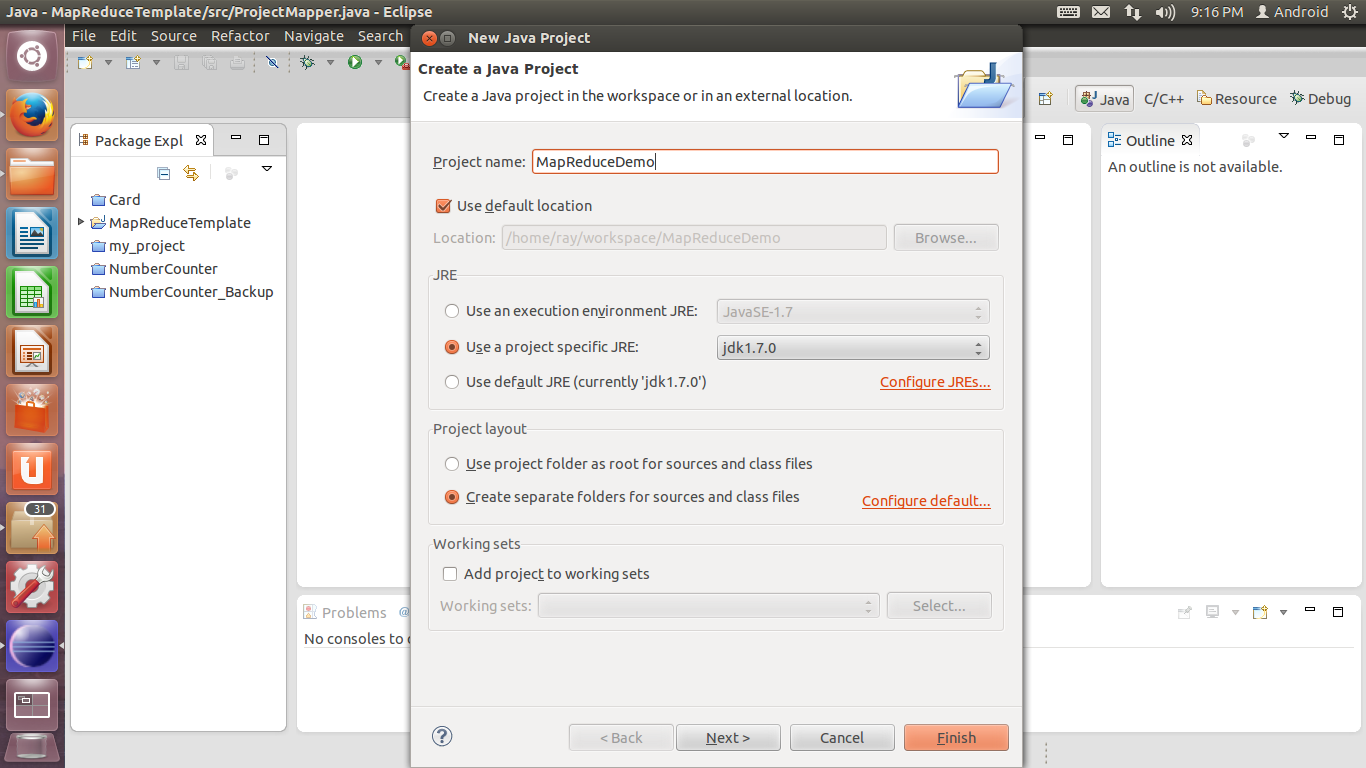
3. 在Java Setting设置中,选择Libraries选项卡,单击Add External JARs,添加工程所需的.jar包。
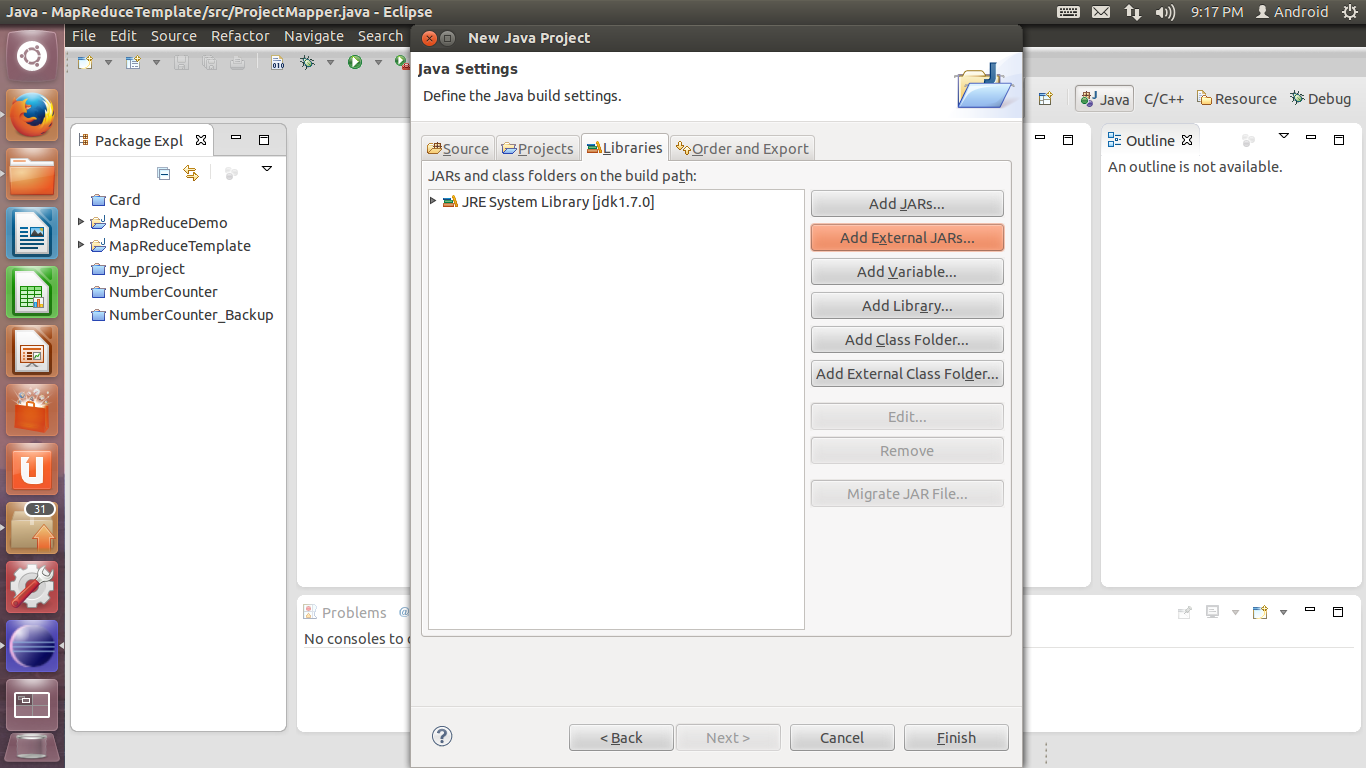
Hadoop 2.3.0中需要添加以下位置的包:
(下面用${HADOOP_HOME}表示hadoop安装路径,*.jar表示该路径下所有.jar包)
${HADOOP_HOME}\share\hadoop\common\hadoop-common-2.3.0.jar
${HADOOP_HOME}\share\hadoop\common\lib\*.jar
${HADOOP_HOME}\share\hadoop\hdfs\hadoop-hdfs-2.3.0.jar
${HADOOP_HOME}\share\hadoop\mapreduce\hadoop-mapreduce-client-app-2.3.0.jar
${HADOOP_HOME}\share\hadoop\mapreduce\hadoop-mapreduce-client-common-2.3.0.jar
${HADOOP_HOME}\share\hadoop\mapreduce\hadoop-mapreduce-client-core-2.3.0.jar\
${HADOOP_HOME}\share\hadoop\mapreduce\hadoop-mapreduce-client-jobclient-2.3.0.jar
${HADOOP_HOME}\share\hadoop\mapreduce\hadoop-mapreduce-client-shuffle-2.3.0.jar
${HADOOP_HOME}\share\hadoop\yarn\hadoop-yarn-api-2.3.0.jar
${HADOOP_HOME}\share\hadoop\yarn\hadoop-yarn-client-2.3.0.jar
${HADOOP_HOME}\share\hadoop\yarn\hadoop-yarn-common-2.3.0.jar
${HADOOP_HOME}\share\hadoop\yarn\hadoop-yarn-server-common-2.3.0.jar
(感觉是不是直接把这些文件夹下所有的.jar文件一股脑全添加进去也是可以的……)
完成后单击Finish,工程创建成功。
4. 在Package Explorer中新建的工程上单击右键,选择New-Class。为了实现WordCount程序,我们需要建立三个类:继承Configured,实现Tool接口的ProjectDriver类,用于进行Job的各项配置,指定Main函数;继承Mapper,实现Map过程的ProjectMapper类;继承Reducer,实现Reduce过程的ProjectReducer类。
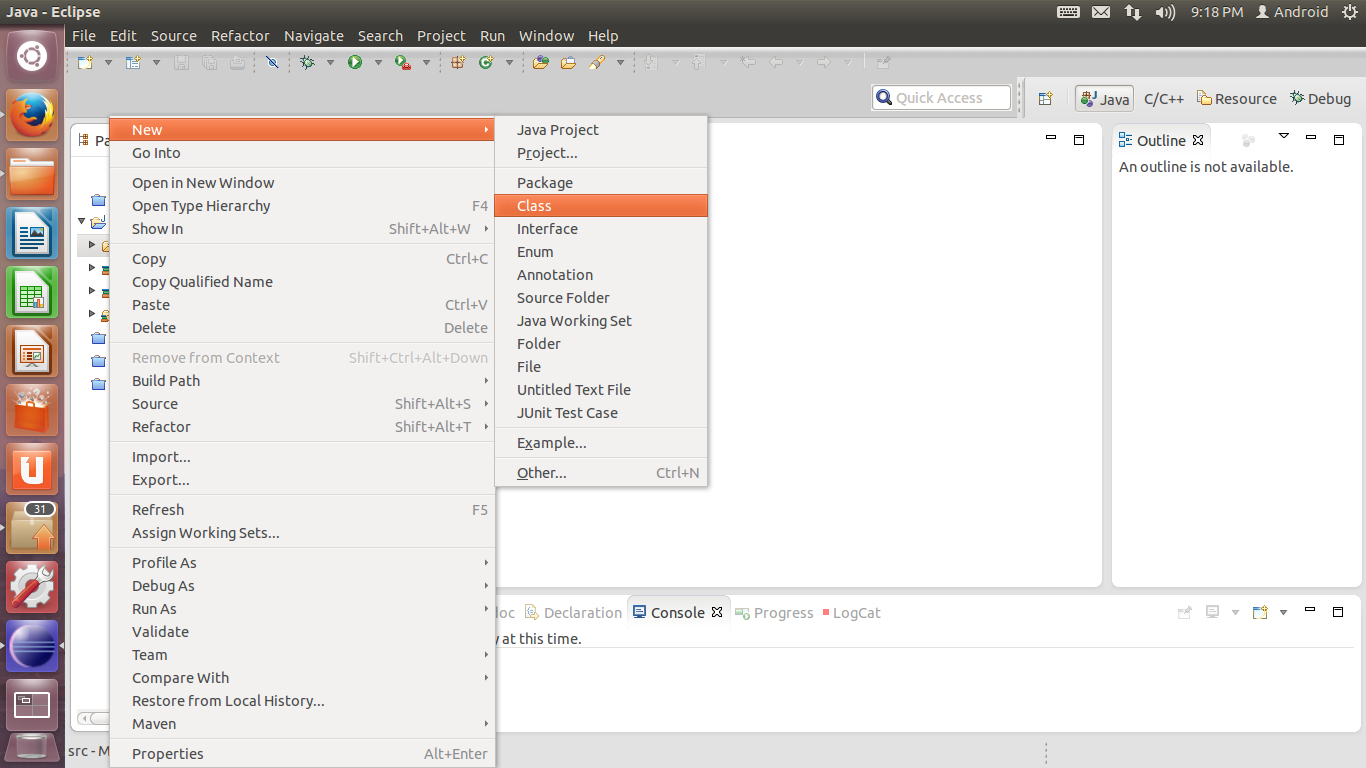
5. 首先创建ProjectDriver类。在Superclass处单击Browse,在Search中输入Configured,添加找到的org.apache.hadoop.conf.Configured;在Interfaces处单击Add,在Search中输入Tool,添加org.apache.hadoop.util.Tool。勾选public static void main(String[] args)选项,单击Finish完成添加。
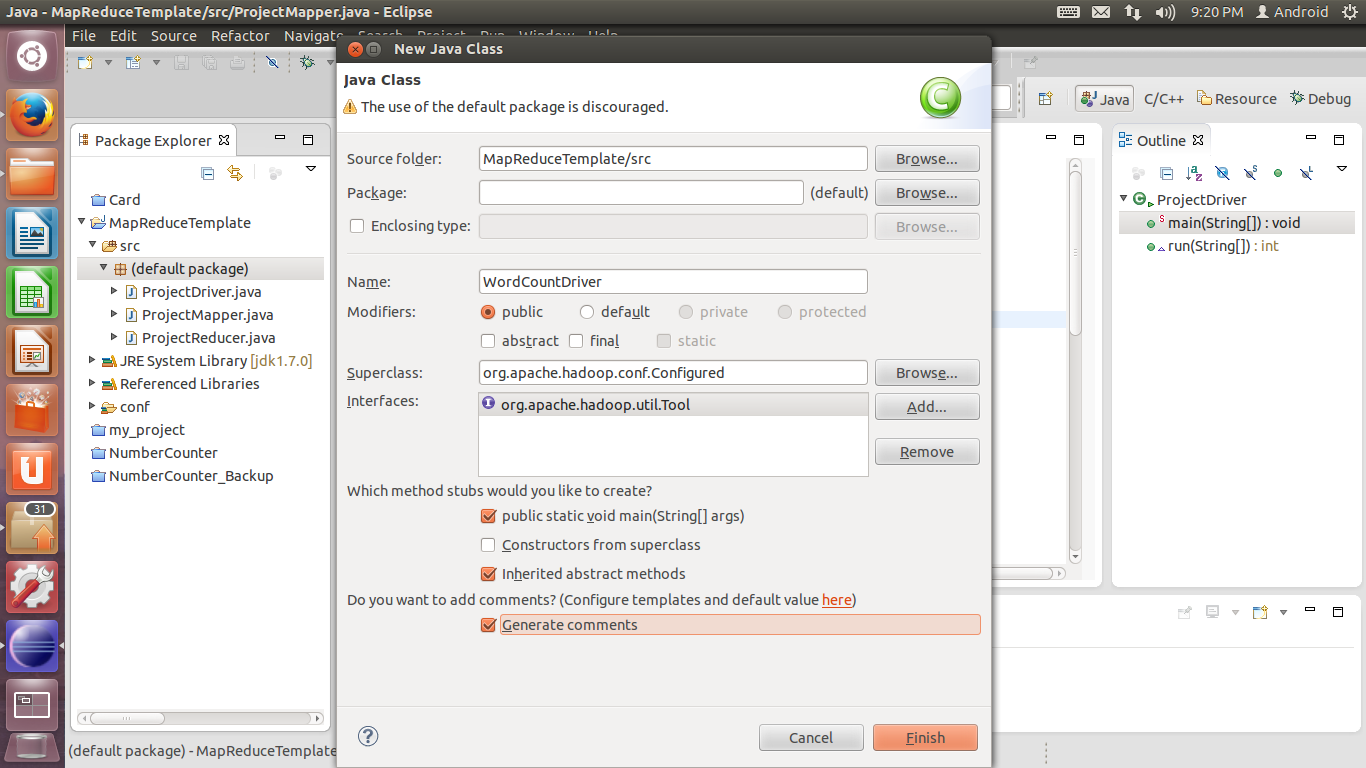
6. 为ProjectDriver类添加以下代码:
/**
* Project Driver - Main & Job Configuration
*/
import org.apache.hadoop.conf.*;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.hadoop.util.GenericOptionsParser;
/**
* @author ray
*
*/
public class ProjectDriver extends Configured implements Tool {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
ProjectDriver pd = new ProjectDriver();
int exitCode = ToolRunner.run(pd, args);
System.exit(exitCode);
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: numbercount <in> <out>");
System.exit(2);
}
Job job = Job.getInstance(conf);
job.setJarByClass(ProjectDriver.class);
job.setJobName(this.getClass().getName());
FileInputFormat.setInputPaths(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
job.setMapperClass(ProjectMapper.class);
job.setReducerClass(ProjectReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
boolean success = job.waitForCompletion(true);
return success ? 0 : 1;
}
}
7. 接下来创建ProjectMapper类。在Superclass处单击Browse,在Search中输入Mapper,添加找到的org.apache.hadoop.mapreduce.Mapper。单击Finish完成添加。
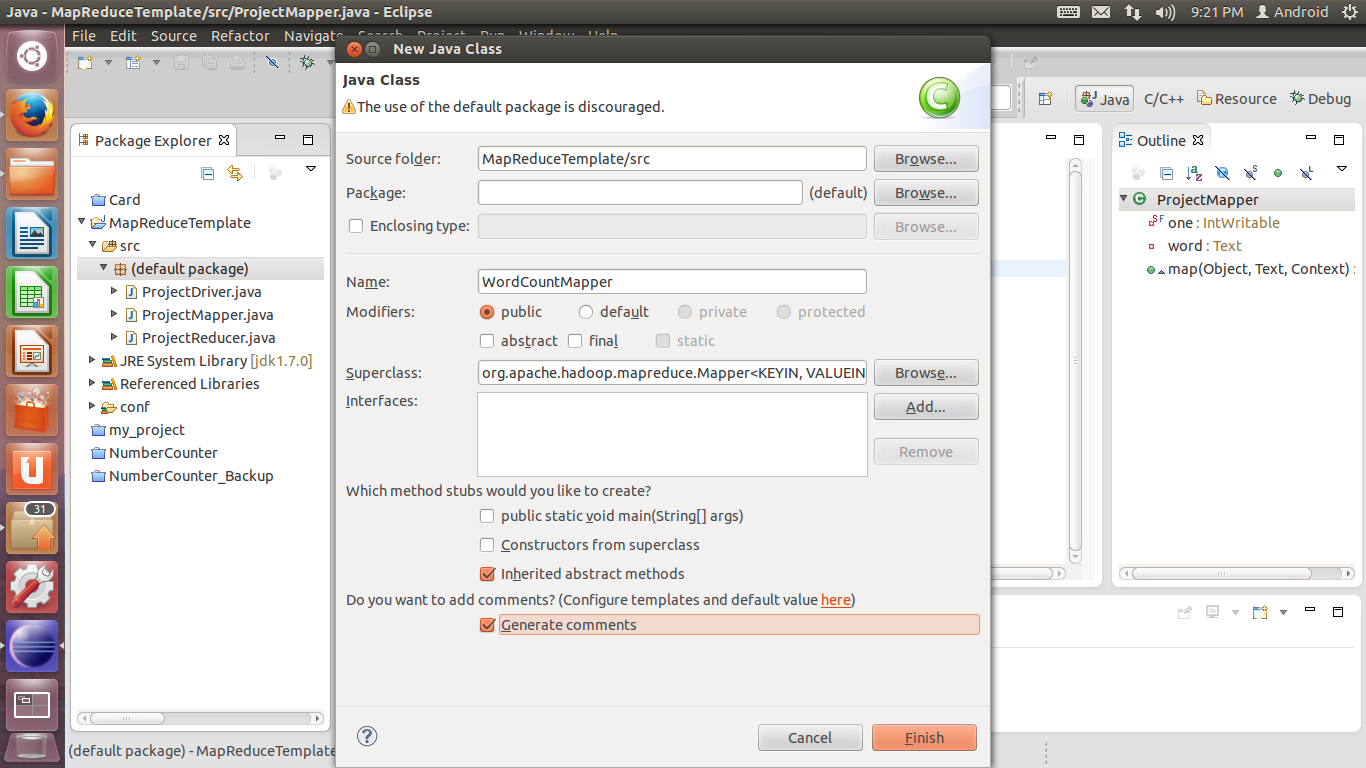
8. 为ProjectMapper类添加以下代码:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* @author ray
*
*/
public class ProjectMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
9. 最后创建ProjectReducer类。在Superclass处单击Browse,在Search中输入Reducer,添加找到的org.apache.hadoop.mapreduce.Reducer。单击Finish完成添加。然后为ProjectMapper类添加以下代码:
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* @author ray
*
*/
public class ProjectReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for(IntWritable val:values){
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
10. 接下来添加log4j的配置文件。打开工程所在目录,新建一个conf文件夹,在文件夹中新建一个名为log4j.properties的文件,将以下代码复制到文件中:
# Autogenerated by Cloudera SCM on Tue Apr 10 13:04:56 CDT 2012
# Define some default values that can be overridden by system properties
hadoop.root.logger=INFO,DRFA,console
hadoop.log.dir=.
hadoop.log.file=hadoop.log
# Define the root logger to the system property "hadoop.root.logger".
log4j.rootLogger=${hadoop.root.logger}, EventCounter
# Logging Threshold
log4j.threshhold=ALL
#
# console
# This is left here because hadoop scripts use it if the environment variable
# HADOOP_ROOT_LOGGER is not set
#
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{2}: %m%n
#
# Daily Rolling File Appender
#
log4j.appender.DRFA=org.apache.log4j.DailyRollingFileAppender
log4j.appender.DRFA.File=${hadoop.log.dir}/${hadoop.log.file}
# Rollver at midnight
log4j.appender.DRFA.DatePattern=.yyyy-MM-dd
# 30-day backup
#log4j.appender.DRFA.MaxBackupIndex=30
log4j.appender.DRFA.layout=org.apache.log4j.PatternLayout
# Pattern format: Date LogLevel LoggerName LogMessage
log4j.appender.DRFA.layout.ConversionPattern=%d{ISO8601} %p %c: %m%n
# Debugging Pattern format
#log4j.appender.DRFA.layout.ConversionPattern=%d{ISO8601} %-5p %c{2} (%F:%M(%L)) - %m%n
#=======
# security audit logging
security.audit.logger=INFO, console
log4j.category.SecurityLogger=${security.audit.logger}
log4j.additivity.SecurityLogger=false
log4j.appender.DRFAS=org.apache.log4j.DailyRollingFileAppender
log4j.appender.DRFAS.File=${hadoop.log.dir}/security/${hadoop.id.str}-auth.log
log4j.appender.DRFAS.layout=org.apache.log4j.PatternLayout
log4j.appender.DRFAS.layout.ConversionPattern=%d{ISO8601} %p %c{2}: %m%n
log4j.appender.DRFAS.DatePattern=.yyyy-MM-dd
# hdfs audit logging
hdfs.audit.logger=INFO, console
log4j.logger.org.apache.hadoop.hdfs.server.namenode.FSNamesystem.audit=${hdfs.audit.logger}
log4j.additivity.org.apache.hadoop.hdfs.server.namenode.FSNamesystem.audit=false
log4j.appender.DRFAAUDIT=org.apache.log4j.DailyRollingFileAppender
log4j.appender.DRFAAUDIT.File=${hadoop.log.dir}/audit/hdfs-audit.log
log4j.appender.DRFAAUDIT.layout=org.apache.log4j.PatternLayout
log4j.appender.DRFAAUDIT.layout.ConversionPattern=%d{ISO8601} %p %c{2}: %m%n
log4j.appender.DRFAAUDIT.DatePattern=.yyyy-MM-dd
#
# FSNamesystem Audit logging
# All audit events are logged at INFO level
#
log4j.logger.org.apache.hadoop.fs.FSNamesystem.audit=WARN
# Jets3t library
log4j.logger.org.jets3t.service.impl.rest.httpclient.RestS3Service=ERROR
#
# Event Counter Appender
# Sends counts of logging messages at different severity levels to Hadoop Metrics.
#
log4j.appender.EventCounter=org.apache.hadoop.log.metrics.EventCounter
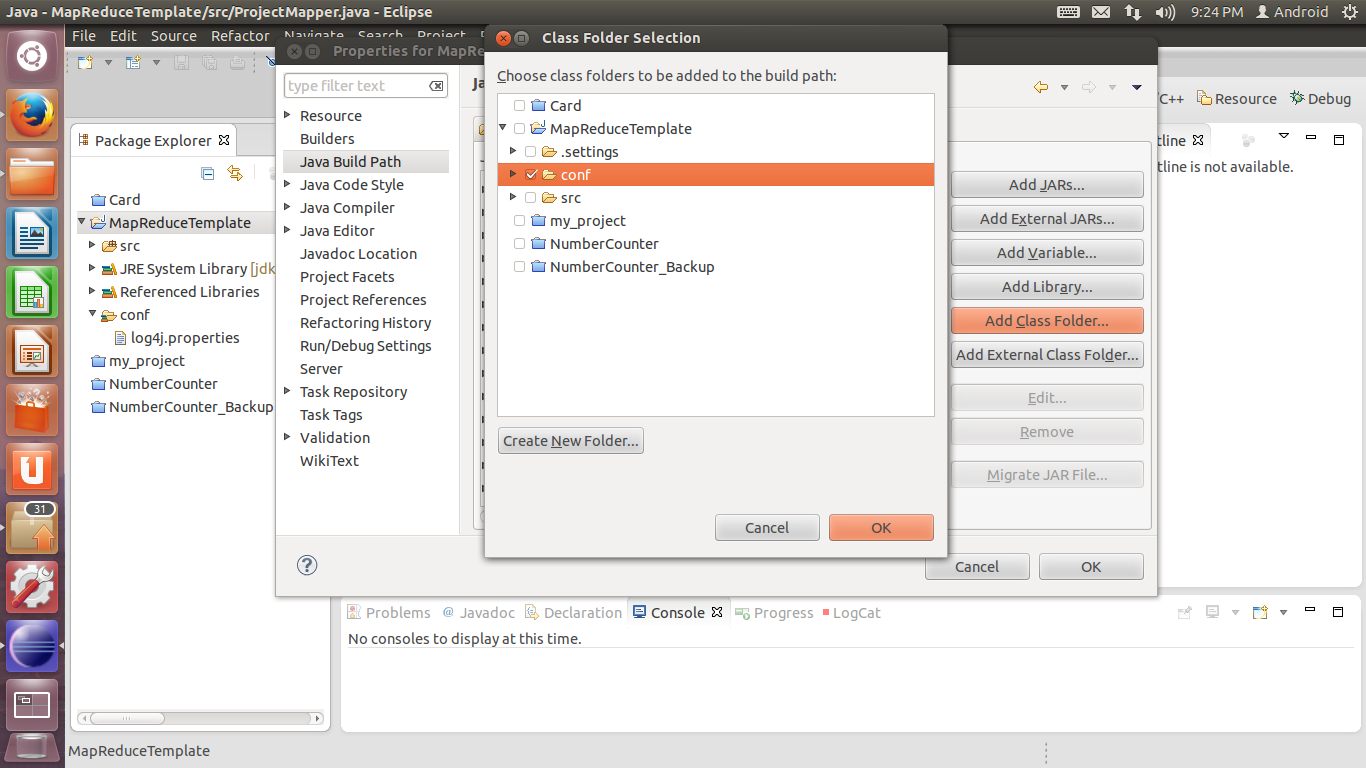
11. 为添加完成后,回到Eclipse。在Package Explorer里面按F5键刷新,会看到刚才创建的conf文件夹。
在工程上点击右键,选择Properties。从左侧找到Java Build Path,单击后在右侧单击Add Class Folder按钮。在弹出的窗口中,勾选conf文件夹,然后单击OK回到Eclipse主界面。
12. 创建Run Configuration。在工程上点击右键,选择Run as-Run Configurations。单击左侧的Java Application后点击上方按钮栏中的New launch configuration按钮创建新配置。
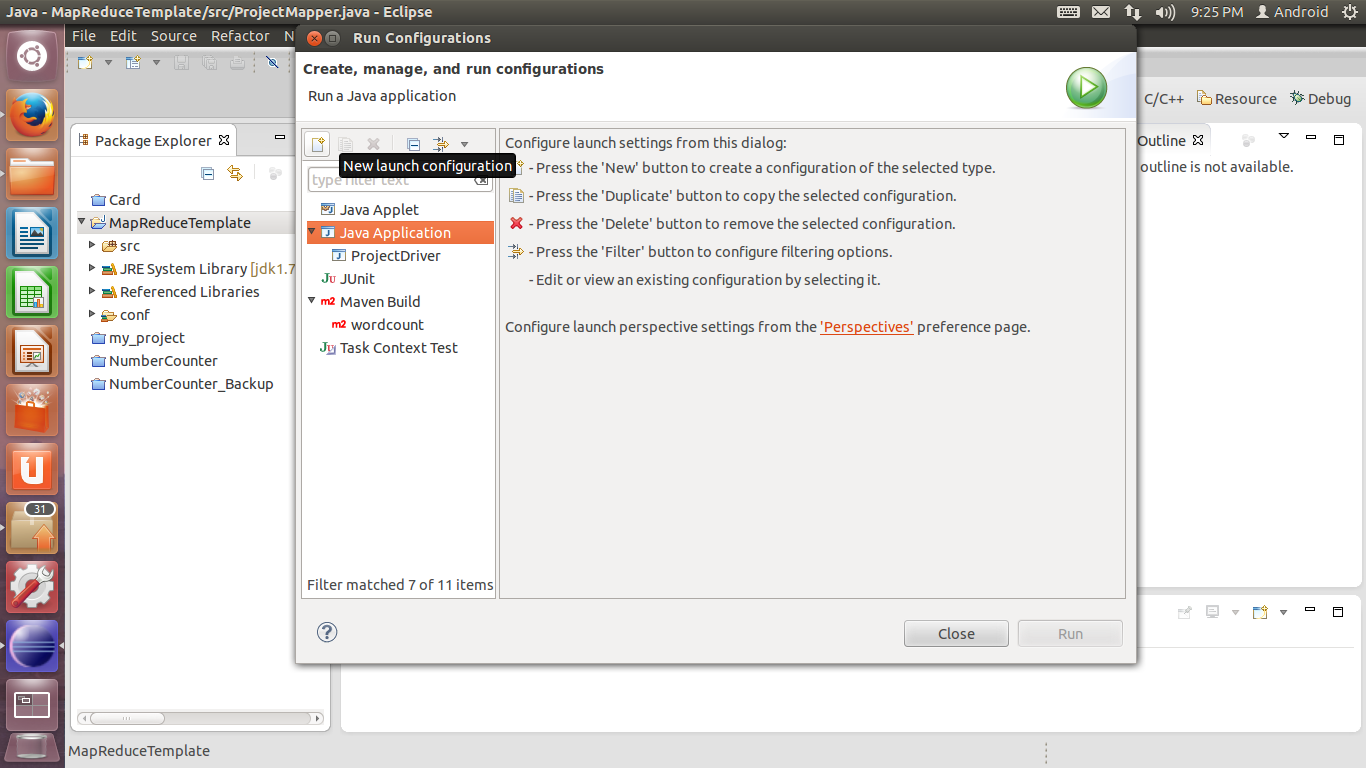
13. 在新创建的配置页面中,选项卡上方的Name可随意填写,作为该debug/run configuration的名称。Main选项卡做如下设置:Project填写当前工程的名称(默认可能已经自动填上了),Main class填写包含Main函数的类的名称(按步骤6的情况应该为ProjectDriver):
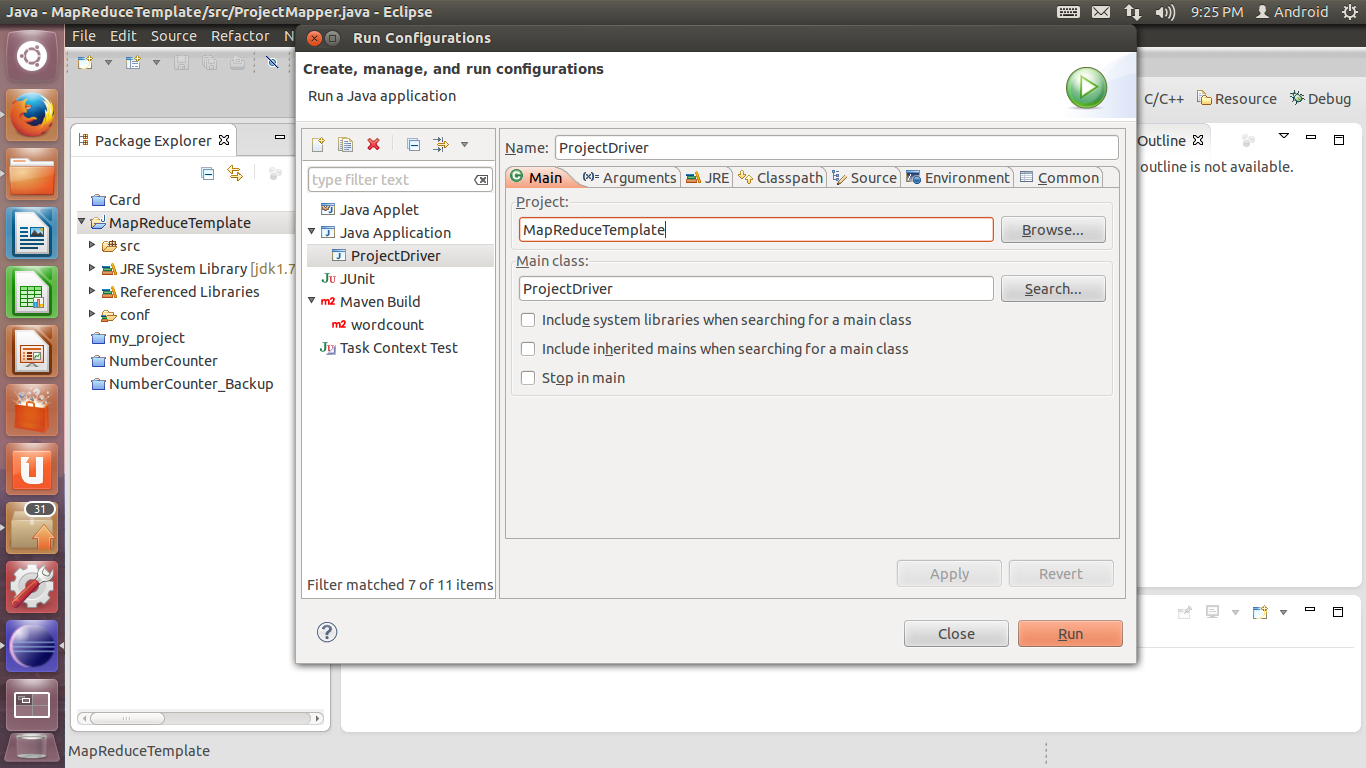
Arguments选项卡做如下设置:Program arguments填写words.txt output。其中,words.txt是WordCount要处理的输入文件,可以随意编写一个,放在工程所在文件夹下(放好后在Package Explorer中按F5刷新之后可以看到);output是输出文件夹的名字。由于调试过程中是以Single Node方式进行的,所以output文件夹的位置就位于工程所在文件夹下面。
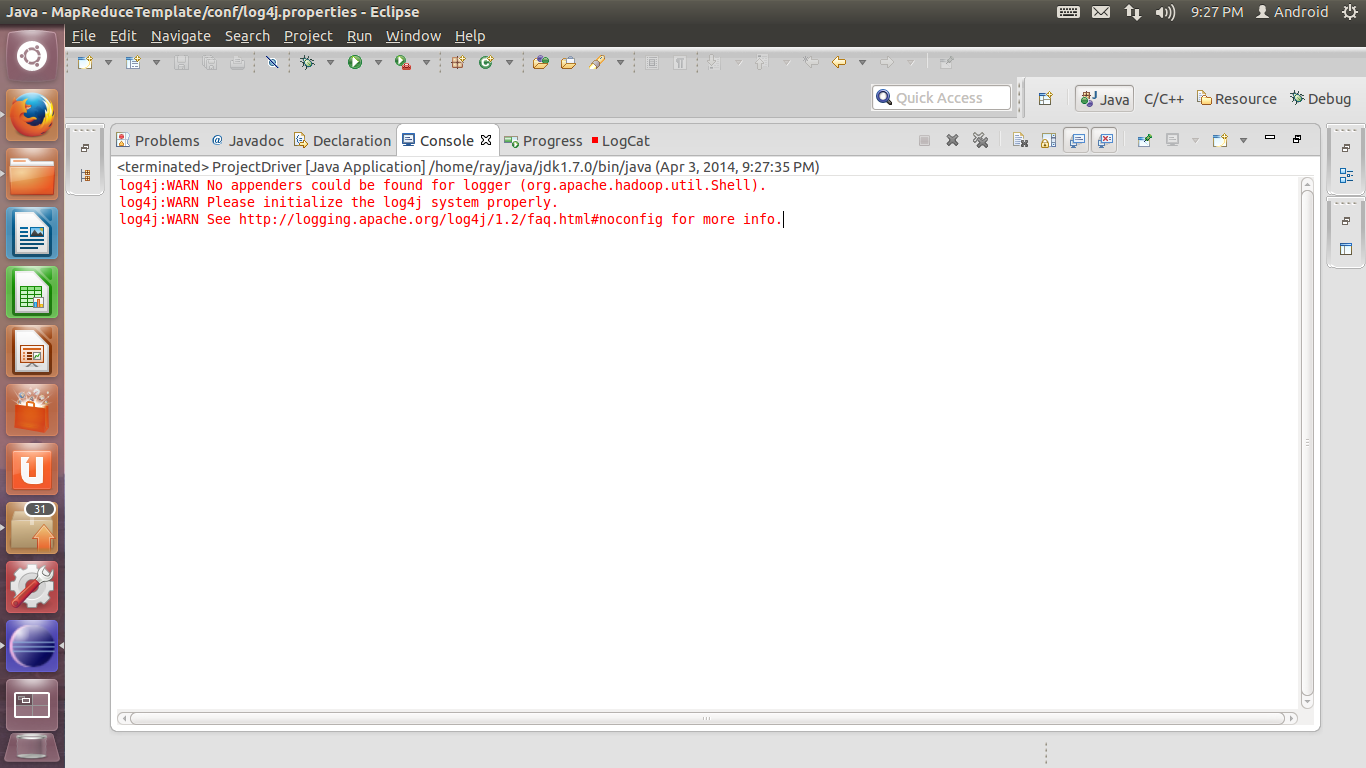
14. 下面我们就可以进行调试和运行了。首先让我们先run一遍。直接点击主界面一排按钮中那个绿色的播放按钮(Run)。如果log4j没有配置或者没有配好,则会出现以下警告:
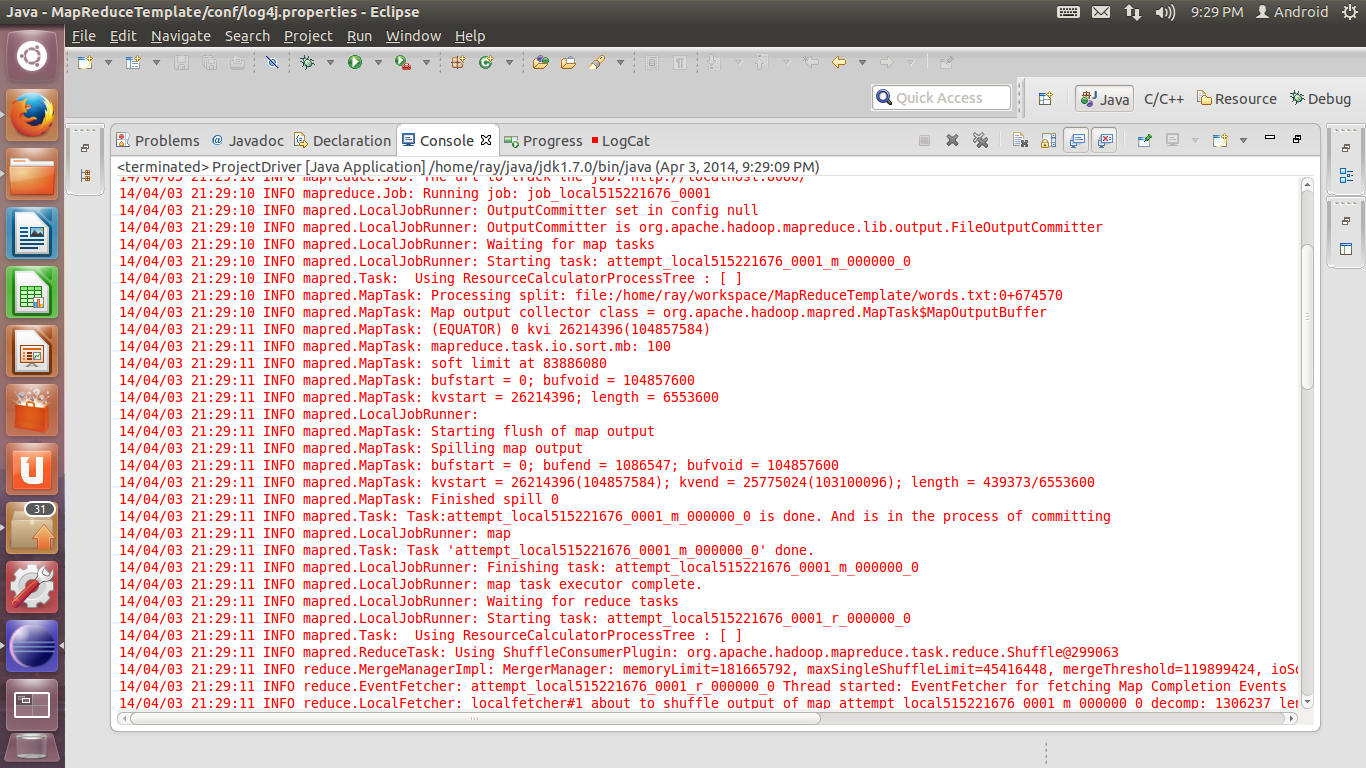
15. 如果log4j配置无误,则会出现下面的输出信息:
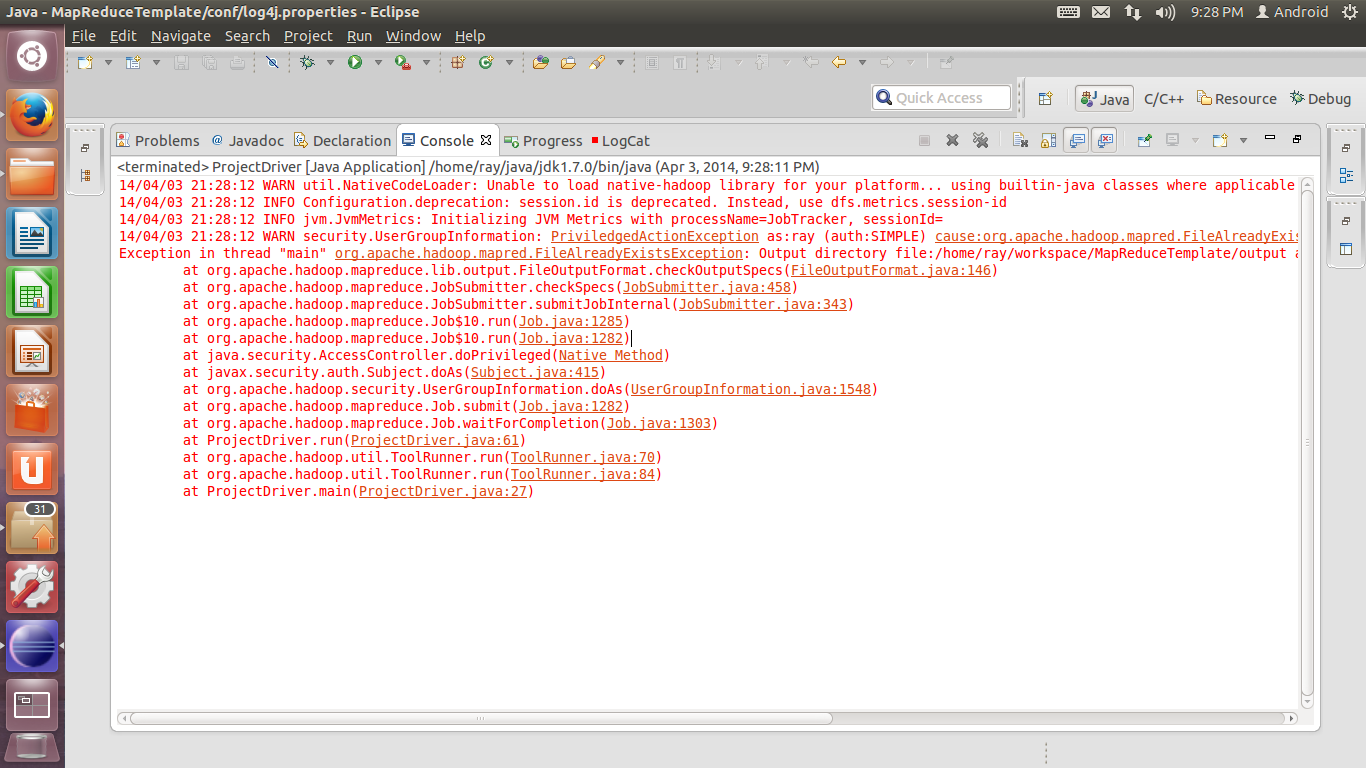
16. 如果出现下图的错误信息,那么说明你已经运行过一次程序了,这时你的工程文件夹下会存在一个output文件夹。程序默认在存在这个文件夹的情况下是不会再次执行的。解决办法有两个,一是直接把这个文件夹删除,二是更改第13步里面Program arguments中的output参数为其他名称,这样程序就会将结果输出至新的文件夹中。
17. 调试程序的方法也很简单。直接在你想要调试的那一行代码前双击鼠标左键,则在此行前会出现一个小圆点表示断点。断点设置好之后,单击主界面按钮栏中的虫子图标(debug),程序运行至设置的断点处则会暂停,然后可以单步执行进行调试了,和普通的程序是一样的。
18. 程序测试无误后,则可以导出为.jar文件了。在工程上点击右键,选择Export…
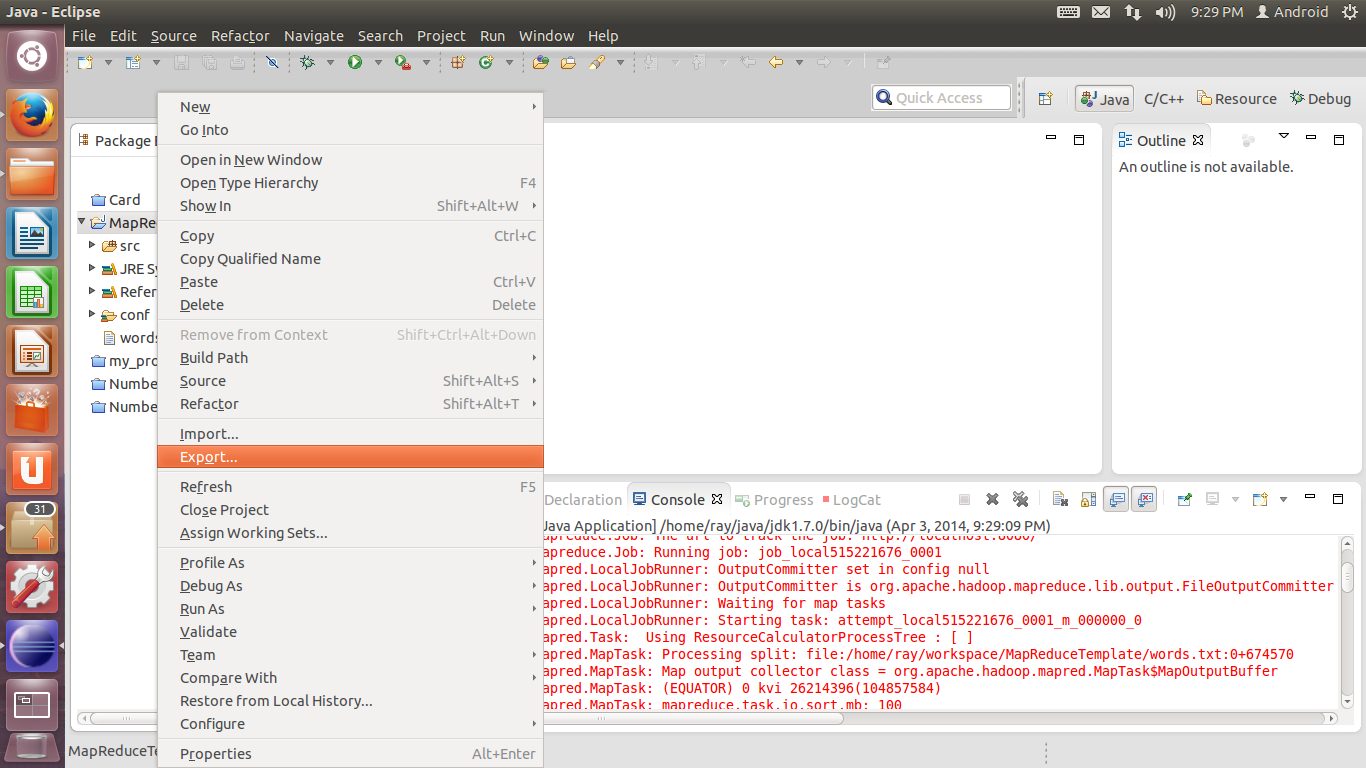
在弹出的窗口中选择Java-JAR file,单击Next。
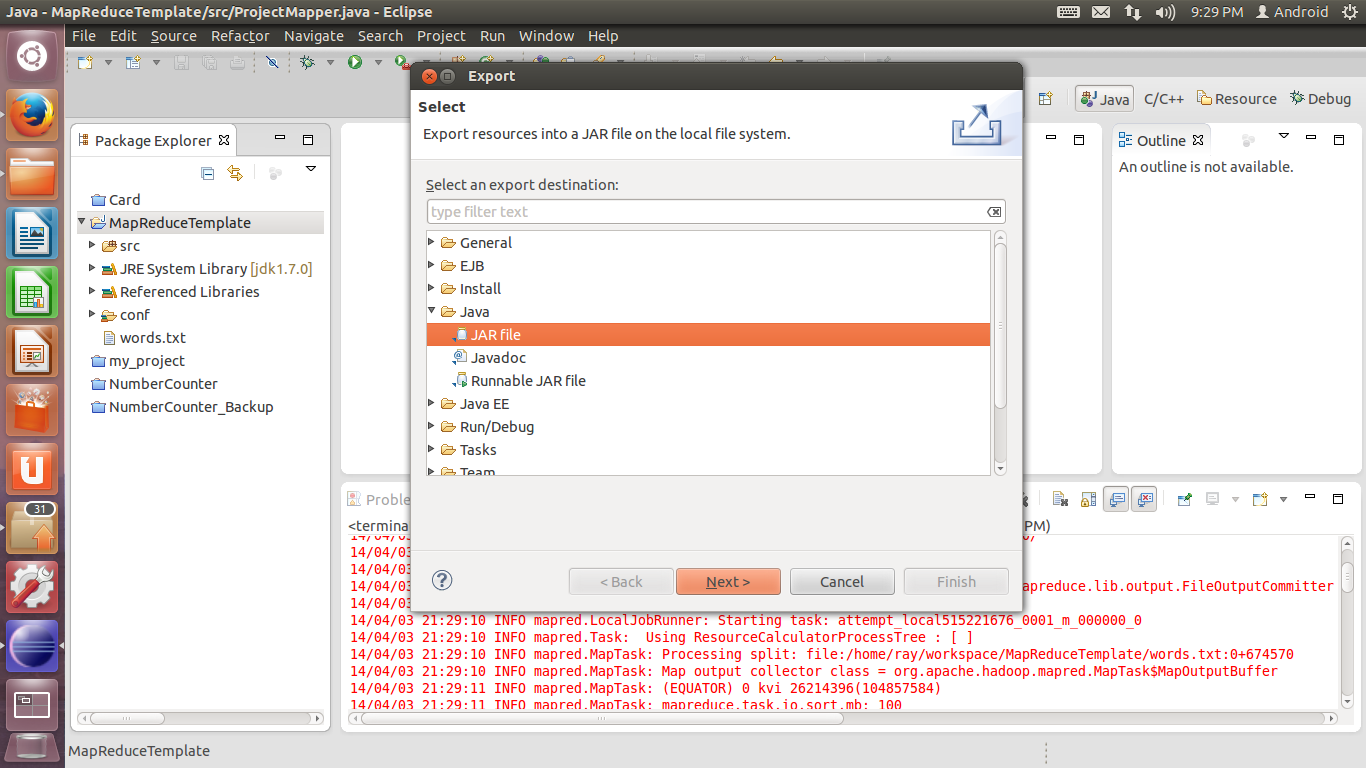
19. 在Select the resources to export中,排除不需要的文件(words.txt是我们程序调试过程中的测试输入,不需要导出到.jar文件中)。在Select the export destination处,设置导出文件的存放目录。单击Next。
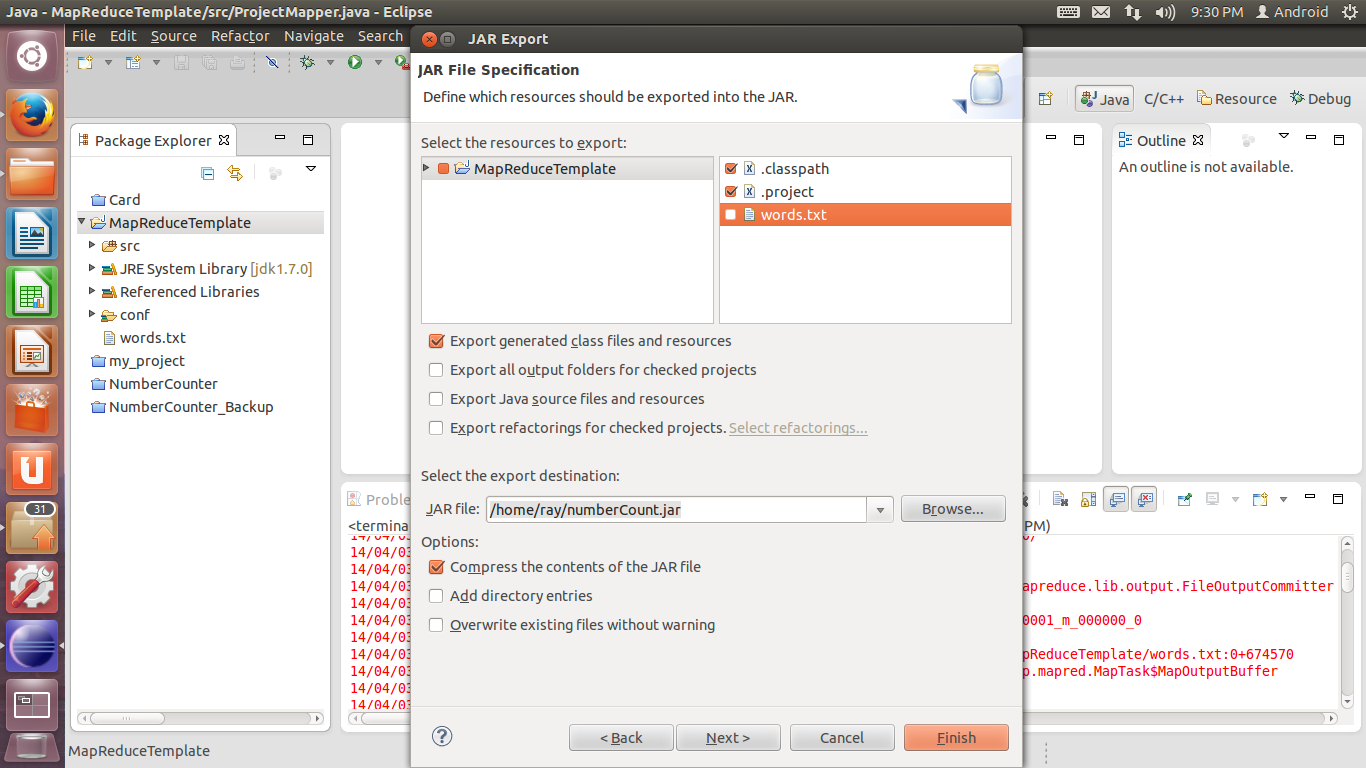
20. JAR Packaging Options不需要做更改,直接点击Next。
21. 在最下方的Main class处设置程序入口。单击Browse,在弹出的窗口中选择包含Main函数的类。按第六步的情况应为ProjectDriver。单击OK,然后点击Finish完成导出。
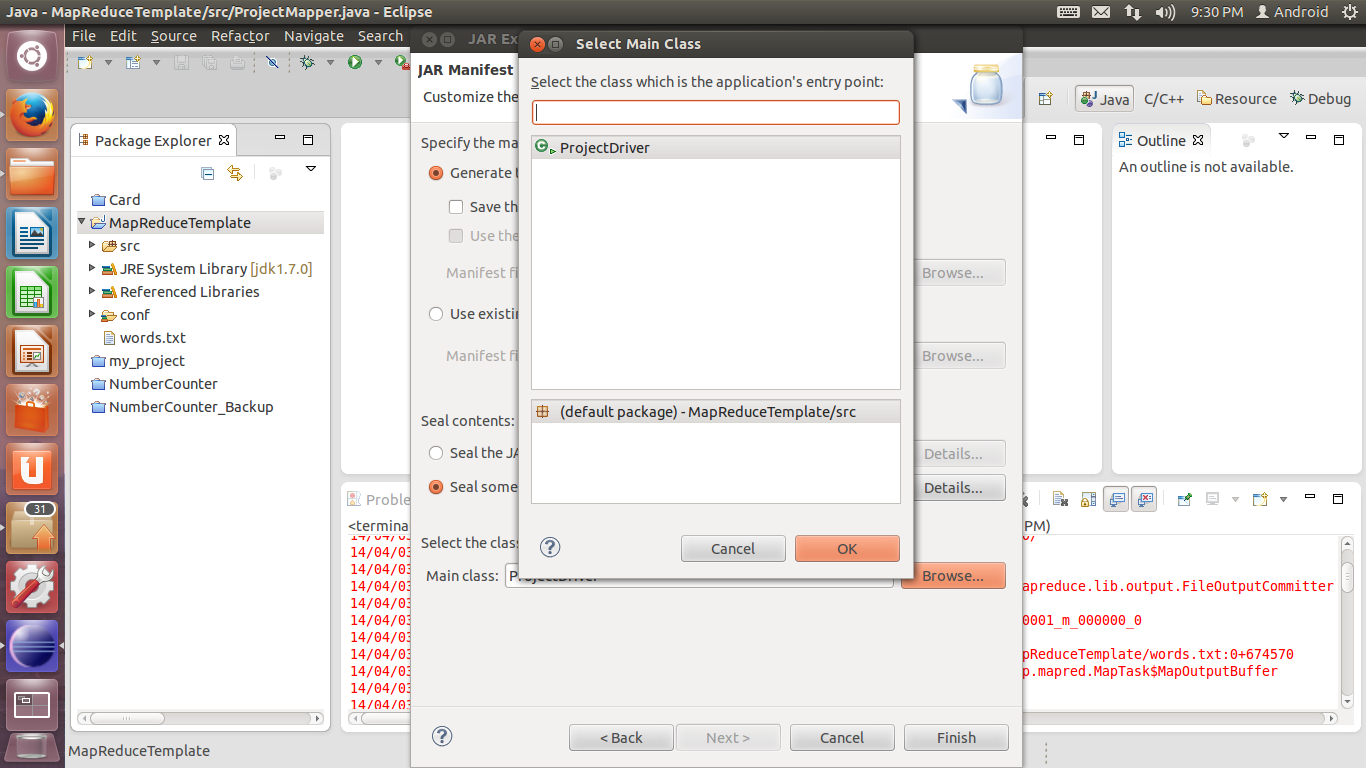
22. 假设生成的文件名为MapReduceDemo.jar,存放于~/demo文件夹下,那么可以输入以下命令测试导出的.jar文件是否正常运行(需要先启动dfs和yarn):
./bin/hadoop jar ~/demo/MapReduceDemo.jar /input /output
前提:HDFS上已经建立了input文件夹,并且向文件夹中上传了待处理的文本文件。
扩展阅读
2023年1月02日 14:15
To debug MapReduce projects in Eclipse, you will need to use the Hadoop Eclipse Plug-in. This diamonds rings near me plug-in allows you to run MapReduce programs in the Eclipse debugger, as well as browse HDFS files and submit MapReduce jobs to a Hadoop cluster. Thank you so much for providing a brief description with a screen shot shared here.